重新認識 Javascript(一)- JS Engine & Runtime
前言
Javascript 寫久了大概都聽過或看過 作用域鏈、執行上下文棧、原型鏈、this,但如何將它們兜在一起說個故事,一直都雲裡霧裡的,所以這個系列的主旨就是想了解它們在程式運行中所扮演的角色與作用,但在這之前我們先來介紹下 Js Engine、Js Runtime,再在後面幾篇各別聊聊它們。
Js Engine
如今 Js Engine 可說是百花齊放,各大瀏覽器均推出自家引擎,我們就以人氣最高 Chrome 推出的 V8 Engine 作為研究對象吧。
先上簡略流程圖:
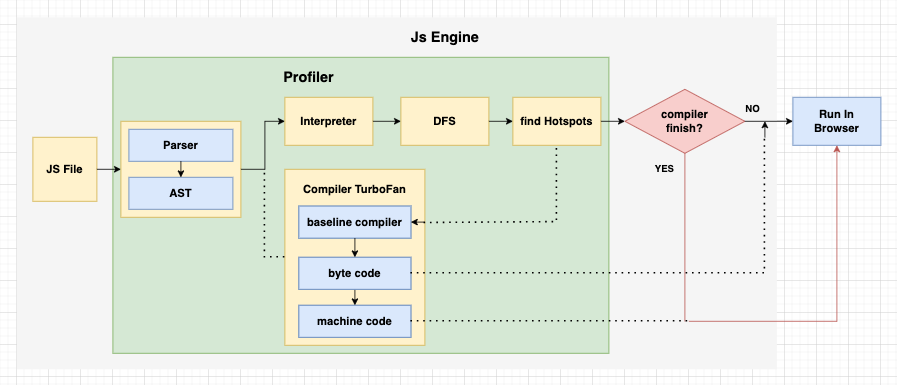
接著讓我們各別說明上圖關鍵部分:
一、解析器(Parser)
先透過 詞法分析 將 JavaScript 解析成 詞法單元(Tokens),再透過 語法分析 識別 語法結構,最後生成 抽象語法樹(AST),為之後的 解釋器(Interpreter) 做準備。
詞法單元(Tokens)
組成一段程式碼的最小單元,如:關鍵字、標識符、運算符、數字和字符串等。
以下方程式碼為例:
const greeting = "Hello, world!";
會被拆解成 const、greeting、=、"Hello, world!"、; 各詞法單元。
語法結構
指的是一段程式碼的組合方式,如:函式名稱、參數有哪些、如何運算…等。
以下方程式碼為例:
function add(a, b) {
return a + b;
}
可以識別出 函式add 擁有 參數a、b 會進行 相加運算 結束時 拋出結果。
抽象語法樹(AST)
結合上方兩者生成程式碼的樹狀表示,以節點表示語法結構,而節點間的關係表示程式碼的層次結構。
以上方 函式add 為例會生成:
FunctionDeclaration
├─ id: Identifier (name: "add")
├─ params:
│ ├─ Identifier (name: "a")
│ └─ Identifier (name: "b")
└─ body: BlockStatement
└─ body: ReturnStatement
└─ argument: BinaryExpression
├─ left: Identifier (name: "a")
├─ right: Identifier (name: "b")
└─ Operator (+)
可參考 AST Explorer 查看完整 AST 樹結構。
二、分析器(Profiler)
會在 解析器 階段解析詞法單元和抽象語法樹時,記錄程式碼的結構和組成,等到 解釋器、編譯器 階段,監測程式的執行並標示熱點程式碼(Hotspots),使其能優先優化可能造成性能瓶頸的區塊。
以下是可能的熱點程式碼標示依據:
-
複雜計算
-
執行時間:即使程式碼沒有頻繁執行,只要它佔據了大部分的執行時間,也會視為一個潛在的熱點。
-
執行頻率:某段程式碼相對被頻繁調用。
function sayHello() { // ... } for (let i = 0; i < 1000; i++) { sayHello(); } function main() { sayHello(); sayHello(); }
以下是 解釋器、編譯器 可能採取的優化策略:
-
內聯緩存(Inline Caching)
多次訪問相同屬性,會導致引擎進行重複的屬性查找操作,這時編譯器會將此屬性的值緩存到一個變量中。當下次訪問相同屬性時,就不需要再進行屬性查找,而是直接使用緩存的值。
// before const person = { name: "Alice" }; console.log(person.name); console.log(person.name); // after const person = { name: "Alice" }; const cachedName = person.name; // 緩存屬性 console.log(cachedName); console.log(cachedName); -
靜態類型推斷(Static Type Inference)
在解釋器執行程式碼時,引擎會記錄它們的值和操作,之後通過分析程式碼的執行路徑和類型推斷,對程式碼進行優化。
// before function add(a, b) { return a + b; } const result = add(5, 10); console.log(result); // after const result = 15; // 靜態類型推斷優化 console.log(result); -
即時函式內嵌(Inline)
將函式調用直接內嵌到調用它的地方,避免重複執行函式調用的過程,從而提高程式碼的執行效率。
// before function multiply(a, b) { return a * b; } function processNumbers(x, y) { return multiply(x, y); } processNumbers(3, 4); // after function processNumbers(x, y) { return x * y; // 即時函式內嵌優化 } processNumbers(3, 4);
三、解釋器(Interpreter)
可以簡單想成是程式碼直譯器,不會有過多優化,以優先執行程式為目標,過程中會有兩部分協同工作:
解釋和執行
解釋器會採用 深度優先遍歷(DFS)策略,從根節點開始,逐步向下遍歷並解釋抽象語法樹每個節點,根據不同類型的節點執行相應的操作,如:變量聲明節點會在作用域中創建變量、函式節點會執行函式…等。
Baseline Compiler
編譯器(TurboFan)的一部分。
在程式碼被解釋器逐行執行時,Baseline Compiler 會動態地將程式碼編譯成字節碼(ByteCode),運行時若再次遇到相同邏輯會改用字節碼,加速進程,如:迴圈執行時就會跳過解釋階段,改用字節碼。
這種方式稱為 即時編譯(JIT Compilation)。
四、編譯器(Compiler)
在 V8 中又被稱為 TurboFan。
根據分析器搜集的熱點數據,通過一系列優化策略,如 內聯緩存(Inline Caching)、靜態類型推斷(Static Type Inference) 和 即時函式內嵌(Inline)…等將字節碼(ByteCode)二次優化,轉換為更高效的機器碼(MachineCode)。
五、取長補短
其實解釋器與編譯器並不能單純想像成兩個獨立階段,而是相互協作的,原因要從二者的優缺點說起:
解釋器的優缺點
優點在於程式碼通過解釋器解釋後就可以直接執行,不用轉換成其他語言,所以啟動非常快。
缺點是運行中碰到重複邏輯都得傻傻地重複執行,容易導致性能瓶頸。
編譯器的優缺點
優點在於經過一系列優化策略後除了精簡邏輯還會將部分程式碼轉成機器碼,加速整體運行速度。
缺點是編譯過程往往需要很多時間。
結合
所以 V8 結合了兩者的優點,運作初期由解釋器快速啟動程式,編譯器在背景根據分析器提供的數據進行第一次優化(字節碼 ByteCode),除了加速解釋器運作,同時預熱後期的優化工作,等漫長的編譯過程完成後,解釋器才交棒給編譯器。
Js Runtime
說了這麼多關於 JS Engine 後我們是不是忘了誰,它讓我們的程式碼可以按照順序執行,同時也幫助 JS 實現非同步操作?它就是 JS Runtime。
JS Runtime 指的是運行環境,它提供程式碼執行所需的基礎設施,使我們的 JS 得以在特定的環境中運行,如:瀏覽器、Node.js。當我們在瀏覽器中打開一個網頁,瀏覽器的 JS Runtime 就會負責執行這些程式碼,並提供了許多其他功能,如:管理內存、處理 DOM、響應用戶交互…等
一樣先上簡略流程圖:
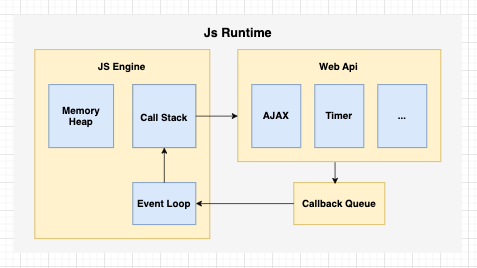
接著讓我們各別說明上圖關鍵部分:
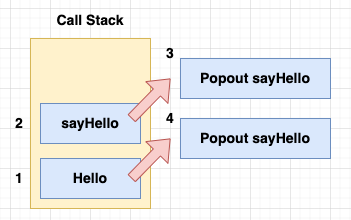
一、調用堆棧(Call Stack)
用於追蹤函式的執行過程,當函式被調用時,其執行上下文(包括變量、參數等)會被壓入調用堆棧,接著執行函式。
過程中採取 先進後出 策略,當函式完成後它會從調用堆棧彈出,返回到上一個調用點。
以下方程式碼為例:
function sayHello(name) {
return "Hello, " + name;
}
function Hello() {
const message = sayHello("Alice");
console.log(message);
}
Hello();
首先將 Hello 壓入調用堆棧,發現內部調用 sayHello,同樣壓入調用堆棧,當 sayHello 完成後從堆棧中彈出,確認 Hello 都完成後也從堆棧中彈出。
二、內存堆棧(Memory Heap)
用於存儲數據,如:對象、數組、變量…等。
基本數據類型:
Undefined、Null、Boolean、Number、String、Symbol、BigInt,儲存於棧內存(Stack Memory)。引用數據類型:
Object、function、Array、Date…等,同時儲存於棧內存(Stack Memory)和堆內存(Heap Memory),取值時會從堆內存(Heap Memory)取得引用,然後透過引用找到棧內存(Stack Memory)中的實際資料。
三、Web api
瀏覽器提供的 api 接口,用於處理瀏覽器環境中的異步操作,常見的有:
-
DOM 操作相關:document.querySelector()、document.createElement()、element.addEventListener()…等。
-
定時器和時間管理:setTimeout()、setInterval()…等。
-
網絡請求和數據傳輸:XMLHttpRequest、Fetch、WebSockets…等。
-
儲存相關:localStorage、sessionStorage、IndexedDB…等。
以上只是 Web Api 提供的部分功能,詳情可參考 Web API 简介。
四、回調隊列(Callback Queue)
當異步操作完成後會將回調函式添加到隊列中,之後透過 事件循環 將函式傳回 JS 的主線程中。如:定時器到期、網絡請求返回…等,都會觸發回調函式的添加。
五、事件循環(Event Loop)
這裡就是宏微任務的交叉路口,瀏覽器運行時會不斷輪詢調用堆棧和回調隊列,確保異步操作在適當的時候被執行。
當調用堆棧為空時(宏任務),事件循環會檢查回調隊列中是否有待處理的回調函式(微任務),如果有,則將其添加到調用堆棧中執行。
瀏覽器的事件循環並不完全是看誰先被呼叫,而是各有不同的優先級,大概是以下順序:
-
定時器(Timer)階段:
理由顯而易見,為確保函式如期完成,定時器事件會最優先被處理。
-
UI 渲染(Render)階段:
接著就是使用者體驗,每當事件從上階段完成後,瀏覽器會盡可能快地進行 UI 渲染,將 DOM 變更反映到網頁上。
-
I/O 階段:
非同步的 I/O 操作,如:網路請求、資源載入和文件讀寫…等。
-
微任務(Microtask)階段:
通常調用堆棧清空時若沒有緊急事件要處理,微任務會優先於下一個事件循環的事件,如:Promise 的回調函式、queueMicrotask…等,當微任務隊列為空時,事件循環才會進入下一個階段。
-
事件處理(Event Handling)階段:
處理各種使用者交互事件,如:滑鼠點擊、鍵盤輸入…等。
-
清理(Cleanup)階段:
用於執行一些清理任務,如:關閉連接、釋放資源…等,為確保其他階段的操作在這之前都已完成,通常為最後階段。
六、結論
從上述我們可以得知,JS 之所以可以做到非同步操作,都要歸功於 Web Api 和 Event Loop 的同心協力,主線程一碰到非同步事件就會立刻丟給 Web Api 處理,它只要確保程式按照正確的順序執行就好。
關於
Js Runtime的執行過程可以根據 所以說event loop到底是什麼玩意兒? 提及的 latentflip 實際在線上嘗試。
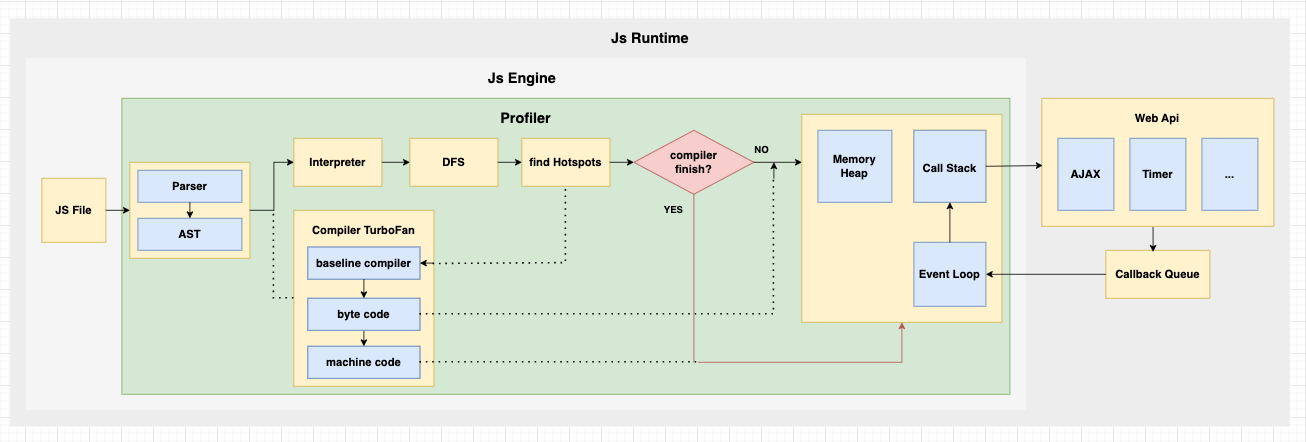
總結
總結 JS Engine、JS Runtime 我們可以得到全圖:
參考文章
JS 原力覺醒 Day02 - JavaScript V8 引擎
深入理解 JavaScript 的 V8 引擎
How JavaScript works: an overview of the engine, the runtime, and the call stack
一探究竟javascript runtime